Knowledge inventory and quality assessment
LLA maps your document collections, formats, storage locations, access patterns, and quality issues. This establishes what the knowledge base must contain and what must be cleaned or structured first.
Most organisations have accumulated years of operational knowledge in documents, emails, SOPs, and policy files — spread across shared drives, email archives, local folders, and legacy systems. When a team member needs to answer a compliance question, find a precedent, or locate a policy, they search manually, ask colleagues, or give up and answer from memory. The knowledge exists. The problem is that nobody can find it reliably, and the answers cannot be verified against the source.
The value of an enterprise AI system is not the model. It is the quality, organisation, and governance of the knowledge base the model draws from. LLA builds the knowledge layer first — ingestion pipeline, access controls, metadata structure, and retrieval logic — then connects the model. This produces answers that can be cited, verified, and audited. It also means the system improves as the knowledge base improves, not as the model changes.
LLA maps your document collections, formats, storage locations, access patterns, and quality issues. This establishes what the knowledge base must contain and what must be cleaned or structured first.
LLA designs the ingestion pipeline: document formats, OCR requirements, metadata extraction rules, chunking strategy, and embedding model selection.
Qdrant or equivalent vector store is configured. Retrieval logic, hybrid search parameters, and result ranking are tuned against your actual documents.
Role-based document access is enforced at the retrieval layer. AI assistant routing connects user queries to the correct knowledge domain.
Every query, retrieval result, and AI answer is logged. Quality monitoring identifies gaps. The knowledge base is updated on a defined cadence.
Role-based permissions, audit logs, validation, secure file handling, approval workflows, and environment-based configuration.
Private cloud, VPS, Docker/Coolify, IIS, or hybrid deployment depending on the customer's security and infrastructure requirements.
LLA positions the AI Hub as a governed knowledge layer: source-traceable, permission-filtered, deployable on enterprise-controlled infrastructure, and sufficiently logged for accountability.
The AI does not just answer. Each response must point back to the underlying document, passage, and context so the user can verify it before acting on it.
Users only receive answers generated from documents they are actually allowed to access. That is the difference between an internal chatbot and a governed AI platform.
LLA supports private deployment where vector storage, model routing, and audit logs remain inside customer-controlled infrastructure, without forcing a public API dependency.
This deployment block is grounded in the AI Hub content model: dedicated vector storage, flexible model routing, controlled document storage, and retrieval/response latency suitable for day-to-day operational work.
This is pulled directly from the AI Hub governance profile: query, retrieval event, and response must all carry user identity, timestamp, and source references before they are acceptable in an enterprise setting.
Most organisations have accumulated years of operational knowledge in documents, emails, SOPs, and policy files — spread across shared drives, email archives, local folders, and legacy systems. When a team member needs to answer a compliance question, find a precedent, or locate a policy, they search manually, ask colleagues, or give up and answer from memory. The knowledge exists. The problem is that nobody can find it reliably, and the answers cannot be verified against the source.
Generic AI assistants fail in enterprise environments for three reasons: they cannot access internal documents, they cannot respect access controls, and they cannot cite the source of their answers. An AI that produces confident, uncited answers from an uncontrolled knowledge base is not a productivity tool — it is a compliance risk. Enterprise AI must be governed: controlled access, traceable answers, and an audit record of every query.
The value of an enterprise AI system is not the model. It is the quality, organisation, and governance of the knowledge base the model draws from. LLA builds the knowledge layer first — ingestion pipeline, access controls, metadata structure, and retrieval logic — then connects the model. This produces answers that can be cited, verified, and audited. It also means the system improves as the knowledge base improves, not as the model changes.
Instead of rolling out broadly from day one, the AI Hub works best when it starts from a specific knowledge domain with real documents, real workflows, and clear verification needs.
Research regulations, internal precedents, contract clauses, and legal texts where source citation and query traceability are mandatory.
Review policies, control compliance evidence, standardize internal answers, and reduce dependency on informal cross-team requests.
Use FAQ archives, playbooks, ticket history, and product documentation to answer faster while staying grounded in approved materials.
Best for teams with many SOPs, checklists, and internal guides where staff must find the right document version for the right role quickly.
Companies with internal document collections, legal references, SOPs, policies, email archives, support knowledge, and operational manuals.
Modular ASP.NET Core services, PostgreSQL-backed operational records, role-based access, API-first integrations, and audit-ready workflows.
Each capability is designed around a specific operational problem - not a generic feature checklist.
Internal knowledge is locked in PDFs, Word documents, scanned files, emails, and legacy formats that AI cannot read directly.
Ingestion pipeline handles PDF, DOCX, XLSX, email, image (OCR), and structured data formats. Documents are processed, chunked, and indexed automatically.
Keyword search fails to find conceptually related documents. Users miss relevant knowledge because they do not know the exact terms to search for.
Hybrid retrieval combines vector similarity search with knowledge graph traversal — finding conceptually related content even when terms do not match.
Generic AI chatbots receive questions from all domains and return answers from an uncontrolled knowledge pool with no access control.
AI routing directs each query to the correct knowledge domain — legal, operational, compliance, product — with domain-specific retrieval and response logic.
AI answers cannot be cited, verified, or challenged because the source documents are not referenced in the response.
Every AI answer includes the source document reference, the specific passage used, and a confidence indicator. Answers can be verified against the original source.
All users can query all documents through a shared AI assistant. Confidential knowledge is exposed to roles that should not have access to it.
Document access permissions are enforced at the retrieval layer. Users can only receive answers sourced from documents within their access scope.
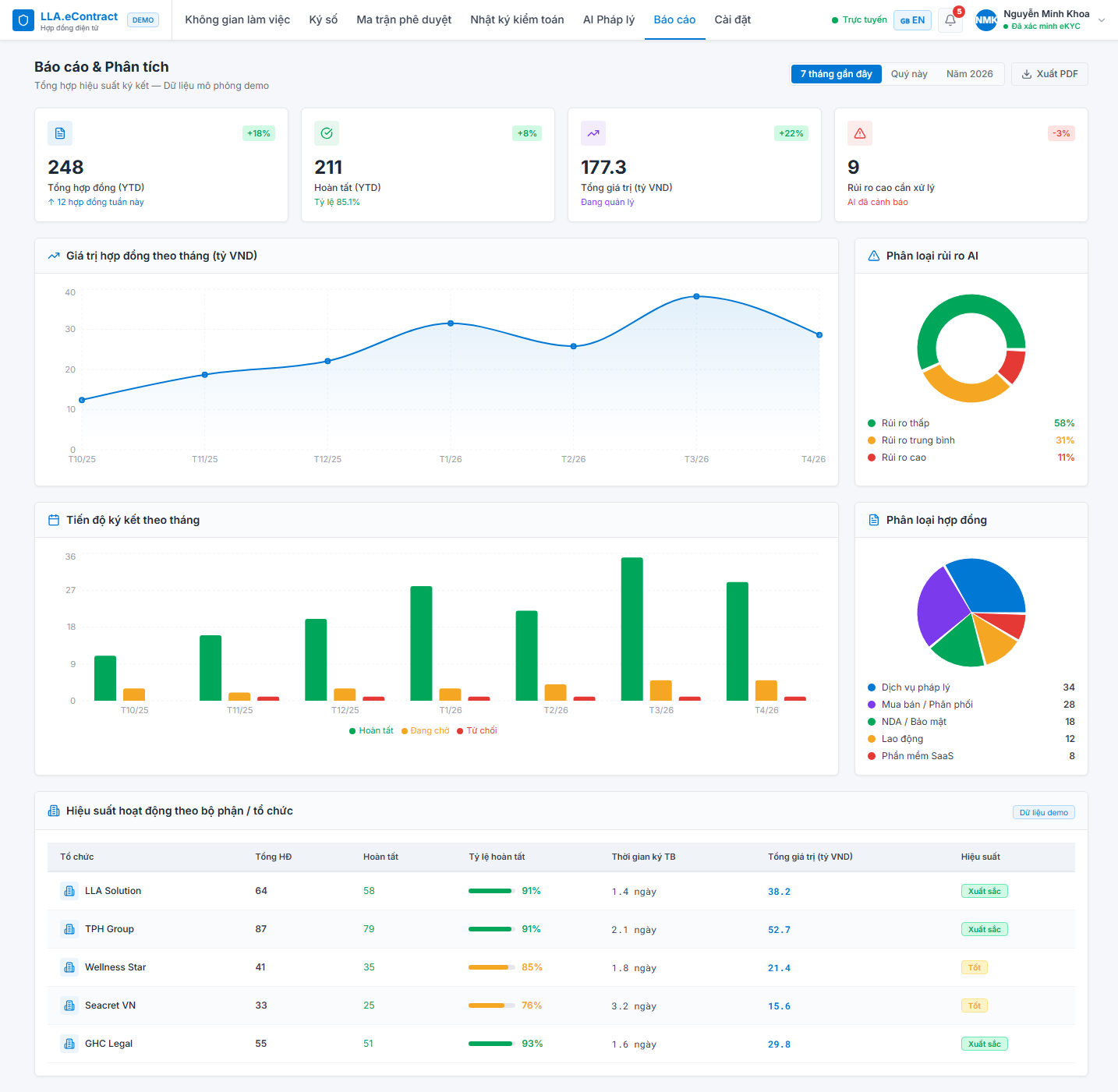
These showcase panels are built from operating screens, workflows, demo data, and control evidence.
These screenshots are used as product evidence: real modules, realistic data, visible workflow states, and operational screens that make the website feel specific to LLA rather than template-generated.
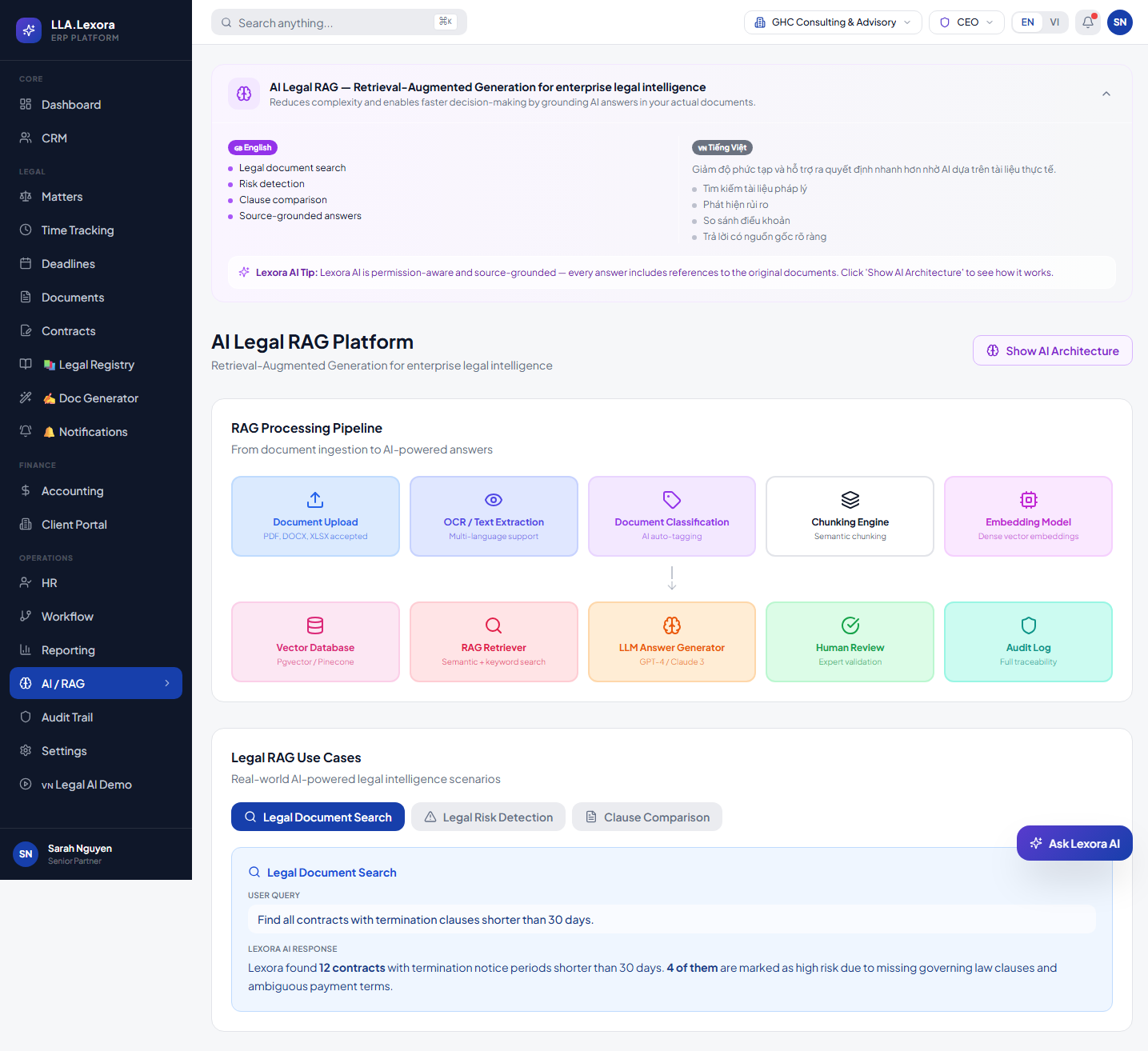
Concrete AI knowledge flow: document upload, extraction, classification, chunking, embeddings, vector database, retrieval, LLM response, human review, and audit traceability.
AI risk review pattern for legal documents with flagged clauses, score, and review workflow.
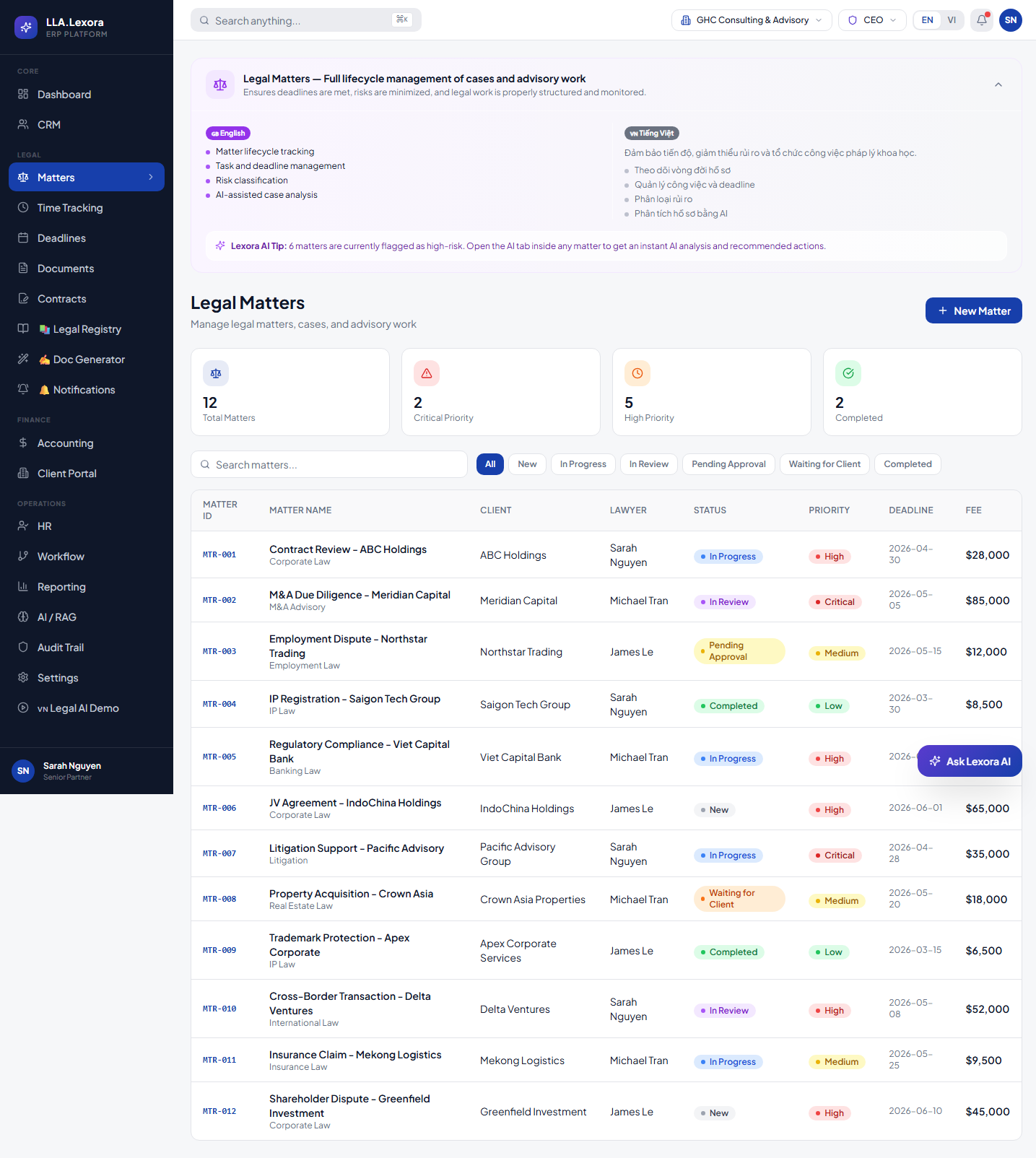
AI-assisted matter triage using legal operations data, deadlines, status, and risk classification.
This platform is designed to connect with the broader LLA ecosystem and third-party systems.
Legal corpus ingestion for matter research, regulatory intelligence, and contract analysis.
Operational SOP and policy knowledge connected to workflow approval and training systems.
AI clause risk analysis on documents within the contract review workflow.
Primary vector database for embedding storage and semantic retrieval.
Flexible AI model routing — cloud models or local deployment based on data sovereignty requirements.
Each phase includes clear delivery gates, ownership, and control checkpoints so operations teams can track progress week by week.
Document inventory completed. Format, quality, and access control requirements assessed.
Delivery milestoneDocument ingestion, OCR, chunking, and embedding pipeline operational. Initial corpus indexed.
Delivery milestoneVector store tuned, hybrid retrieval configured, AI assistant routing connected.
Delivery milestoneAccess controls enforced, audit logging active, quality monitoring configured. Go-live.
Delivery milestoneEach function gets specific, measurable outcomes - not vague benefits.
LLA AI Knowledge Hub enforces access controls at the document ingestion, retrieval, and response layers. Users can only receive AI answers sourced from documents they are authorised to access. Every query, retrieval event, and AI response is recorded in the audit log with user identity, timestamp, and source document references. AI answers cannot be presented without source attribution. The platform can be deployed entirely on customer-controlled infrastructure with local AI models — no mandatory external API dependency.
LLA builds the knowledge layer first — ingestion, structure, and access controls — before connecting the AI model.
LLA AI Hub enforces access controls at the retrieval layer. Users cannot access documents outside their permission scope through AI queries.
Every AI answer is source-attributed and auditable — designed for regulated environments where AI decisions must be verifiable.
LLA supports full private deployment with local AI models — no mandatory external API dependency.
LLA has built AI knowledge systems for legal, compliance, and operational knowledge domains — not generic chatbot deployments.
Yes. LLA uses the product foundation as a starting point, then adapts workflows, data fields, roles, integrations, and reports to the customer's operating model.
Yes. LLA supports private deployment using Docker/Coolify, IIS, PostgreSQL, object storage, and customer-controlled infrastructure when needed.
The architecture supports English and Vietnamese content, including translated entity slugs for public detail pages.
For the AI Hub, the right first step is not a demo. It is a review of documents, access control, knowledge domains, and deployment architecture so the system is scoped correctly.